 Photo by
Photo by Hace unos días me topé con una base de datos con información estadística de todos los equipos, ligas y jugadores de fútbol europeos. No soy amante del futbol, pero sí de los datos y de su análisis, y como este fin de semana he tenido tiempo y tenía ganas de meterle mano a algunas herramientas que tenía medio oxidadas, he decidido hacer algo con ellos.
Mi propósito como total desconocedor de jugadores de fútbol es encontrar similitudes entre jugadores de La Liga sin haber visto ni un sólo partido y sin conocer más que a dos o tres jugadores de oídas. A ver si lo consigo.
Los datos
La base de datos contiene información estadística de jugadores de fútbol en ligas europeas. Estas estadísticas se dividen en cuatro grupos:
1. Generales
- Edad, posición, altura, peso
- Partidos jugados (enteros o una parte), minutos jugados
- Goles, asistencias, disparos a puerta totales
- Tarjetas rojas y amarillas
- Balones ganados en el aire, % de pases buenos
- Número de veces considerado mejor jugador del partido
2. Defensivas
- Entradas, intercepciones, faltas cometidas por partido
- Fueras de juego ganados, despejes, regateos recibidos por partido
- Disparos bloqueados por partido
- Goles en propia puerta
3. Ofensivas
- Disparos a puerta por partido, pases clave por partido
- Regateos por partido, controles malos
- Faltas a favor por partido, fueras de juego por partido
- Controles malos por partido, desposesiones por partido
4. Pases
- Pases y pases clave por partido
- Porcentaje pases buenos
- Centros, pases largo y pases al hueco por partido
En total, contamos con unos 30 atributos cuantificables por cada jugador. ¿Algo podremos hacer, no?
Un primer vistazo
Antes de entrar en detalle, lo primero que vamos a hacer es generar una matríz de correlación: esta matriz nos permite ver de una forma muy visual qué valores tienen impacto en otros. De aquí esperamos ver cosas como que los jugadores altos ganan más balones en el aire que los bajos o que los jugadores que hacen más faltas reciben más tarjetas. Estas suposiciones no tienen porqué ser ciertas, pero nos pueden ayudar a detectar si hemos hecho algo mal.
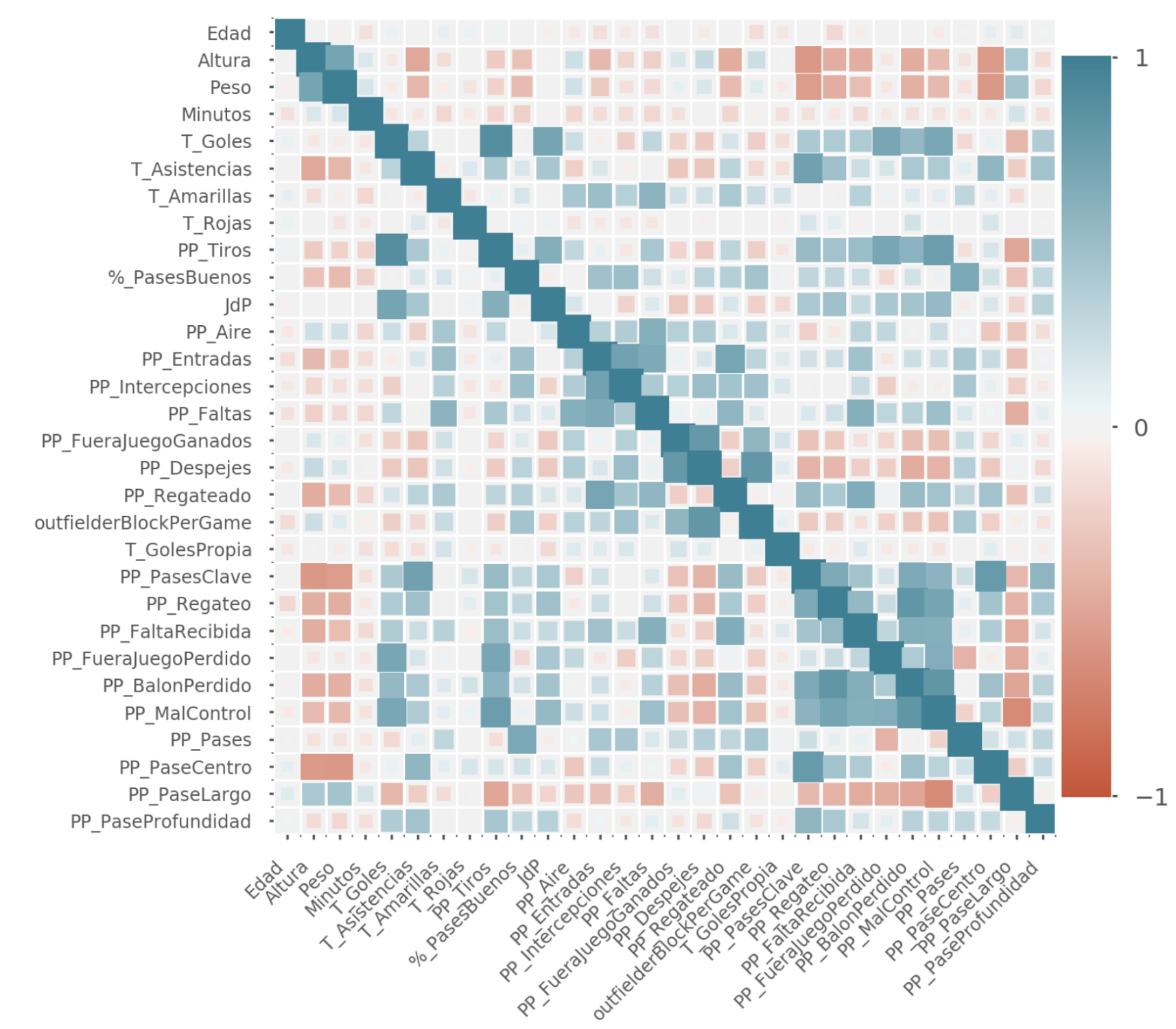
En esta matriz, el tamaño de cada cuadrado representa una correlación entre 0% y 100%. Los colores azules implican una correlación positiva:
- Goles + JdP: Los jugadores que marcan más goles suelen ser los que consiguen el Mejor Jugador Del Partido
- PP_Regateado + PP_Entradas: Los jugadores a los que regatean hacen más entradas. Seguramente porque juegan en la defensiva.
Y a la inversa, los colores más rojos implican correlaciones negativas:
- Altura + PP_PaseCentro: Claramente los jugadores altos no hacen muchos centros, porque deben ser ellos los que están recibiendo.
- PP_PasesClave + PP_Despejes: Despejar es cosa de defensas, poner pases de gol no.
Sin hacer ningún análisis exhaustivo, parece que las correlaciones tienen sentido, por lo que parece que los datos son fiables. Es un buen comienzo.
Limpieza de Datos
Cuando trabajamos con grandes volúmenes de datos es importante entender que no todos los datos nos valen, y los que valen muchas veces no están preparados para ser usados. En casos como este en el que tenemos datos muy dispares en su naturaleza (alturas en cm, porcentajes de pases buenos, número de goles, etc.) es importante normalizar y escalar estos datos para que no acabemos comparando peras con manzanas.
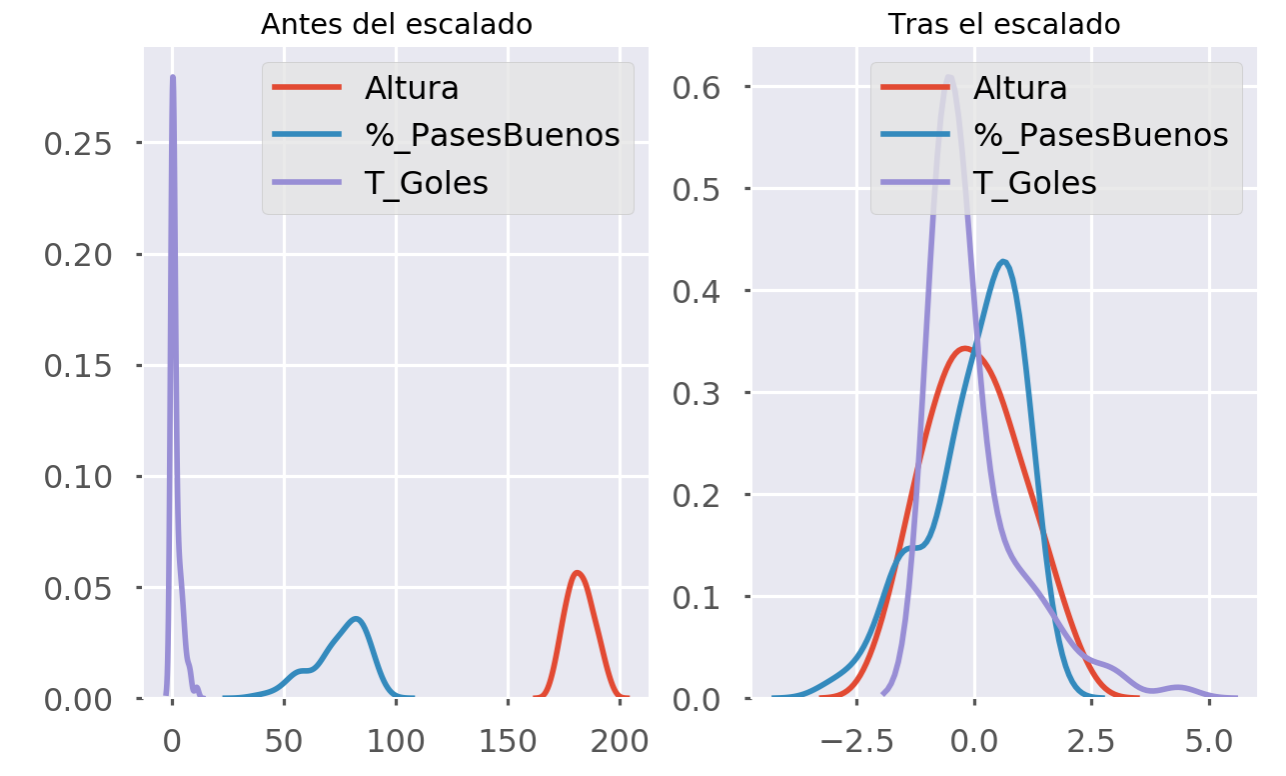
Como vemos, antes del escalado teníamos tres atributos totalmente dispares que nos complicaban su comparación: los jugadores marcan entre 0 y 20 goles, pero su porcentaje de acierto en pases es de entre 0% y 100%, mientras que sus alturas van desde 160cm hasta 200cm. Al escalarlos, todos los valores se mueven ahora entre -5 y 5. Han perdido su “naturaleza”, pero no la necesitamos para nuestro análisis.
Por otro lado, tenemos información de más de 500 jugadores. Realmente no necesitamos usarlos todos. Además, cualquier representación gráfica que hiciéramos con todos ellos sería inteligible. Por ello, vamos a usar en nuestro estudio sólo los jugadores que han jugado más minutos. Ponemos el límite en el percentil 80, que en nuestro set de datos son 1.192 minutos. Lionel Messi no entraba por haber jugado sólo 900 minutos, pero como sé que alguno lo echaría de menos lo he añadido también.
Existen datos que realmente no nos aportan mucha información del “comportamiento” del jugador, sino más bien de su físico o situación. No nos interesa usar atributos como la altura, el peso, la edad o los minutos jugados. Todos los atributos que no son un resultado del propio juego del jugador, los eliminamos.
Por último, para hacer la representación más visual, he asignado a cada jugador una única posición principal aunque jueguen en distintas posiciones. Para simplificarlo, he usado solo 4 posiciones: portero, defensa, centro y delantero. Si un jugador ha jugado en varias posiciones, usaré solo la primera de la lista. El atributo de posición no se usará en ningún momento más allá de para aplicar colores a los jugadores.
Simplificación de atributos
Trabajar con 27 atributos por jugador nos limita mucho la capacidad de generar reportes visuales que nos digan algo. Además, como vimos arriba hay muchos valores muy relacionados entre ellos y que aportan poco valor. Para simplificar todo esto, usaremos lo que se conoce como ACP o Análisis de Componentes Principales. El ACP nos ayudará a crear dos nuevos atributos que recojan de la mejor forma posible la información contenida en los 27 originales.
Sin entrar en detalles técnicos y con la intención de hipersimplificar, imaginemos que todas estos atributos pudieran agruparse en “Capacidad de marcar goles” y “Capacidad de que no me marquen goles”, dos grupos de capacidades totalmente distintas no correlacionadas. Seguramente los tiros a puerta, los fuera de juego o los regates tengan mucho que ver con la primera; las faltas, las tarjetas o los despejes tienen que ver con la segunda. Pero lo más importante es que la capacidad de tirar a puerta guarda muy poca relación con la capacidad de hacer despejes. El objetivo del ACP es darnos estos dos grupos para poder trabajar en dos dimensiones en vez de 27. Los llamaremos Componente Principal 1 y 2 (CP1 y CP2)
Técnicamente, el ACP busca la proyección según la cual los datos queden mejor representados en términos de mínimos cuadrados. Esta convierte un conjunto de observaciones de variables posiblemente correlacionadas en un conjunto de valores de variables sin correlación lineal llamadas componentes principales.
Wikipedia
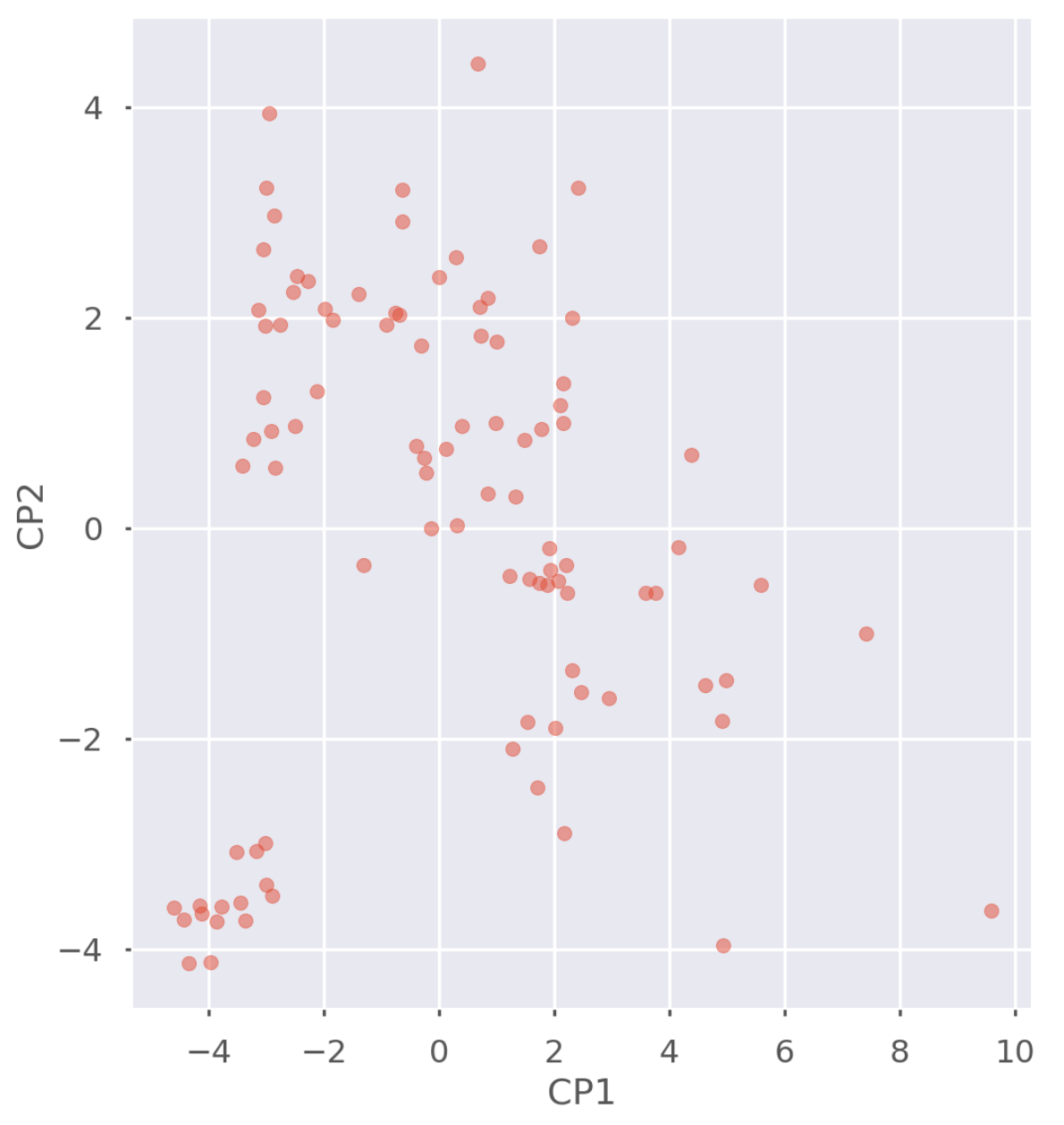
Tras el cálculo de ACP, ya podemos mostrarlos en un gráfico donde cada punto representa un jugador, y su posición en el gráfico viene dada por sus Componentes Principales. Observamos en la esquina inferior izquierda un grupito de jugadores parecidos: ¿serán los delanteros? ¿los porteros? ¿los altos? ¿los que regatean más? No lo sabemos, lo que sabemos es que ese grupo de jugadores se parecen mucho. ¿Y qué pasa con ese que está sólo en la esquina inferior derecha?
Vamos a aplicar un color distinto a cada posición (porteros negro, defensas rojo, centros amarillo, delanteros verde) y vamos a añadir los nombres al lado de cada punto.
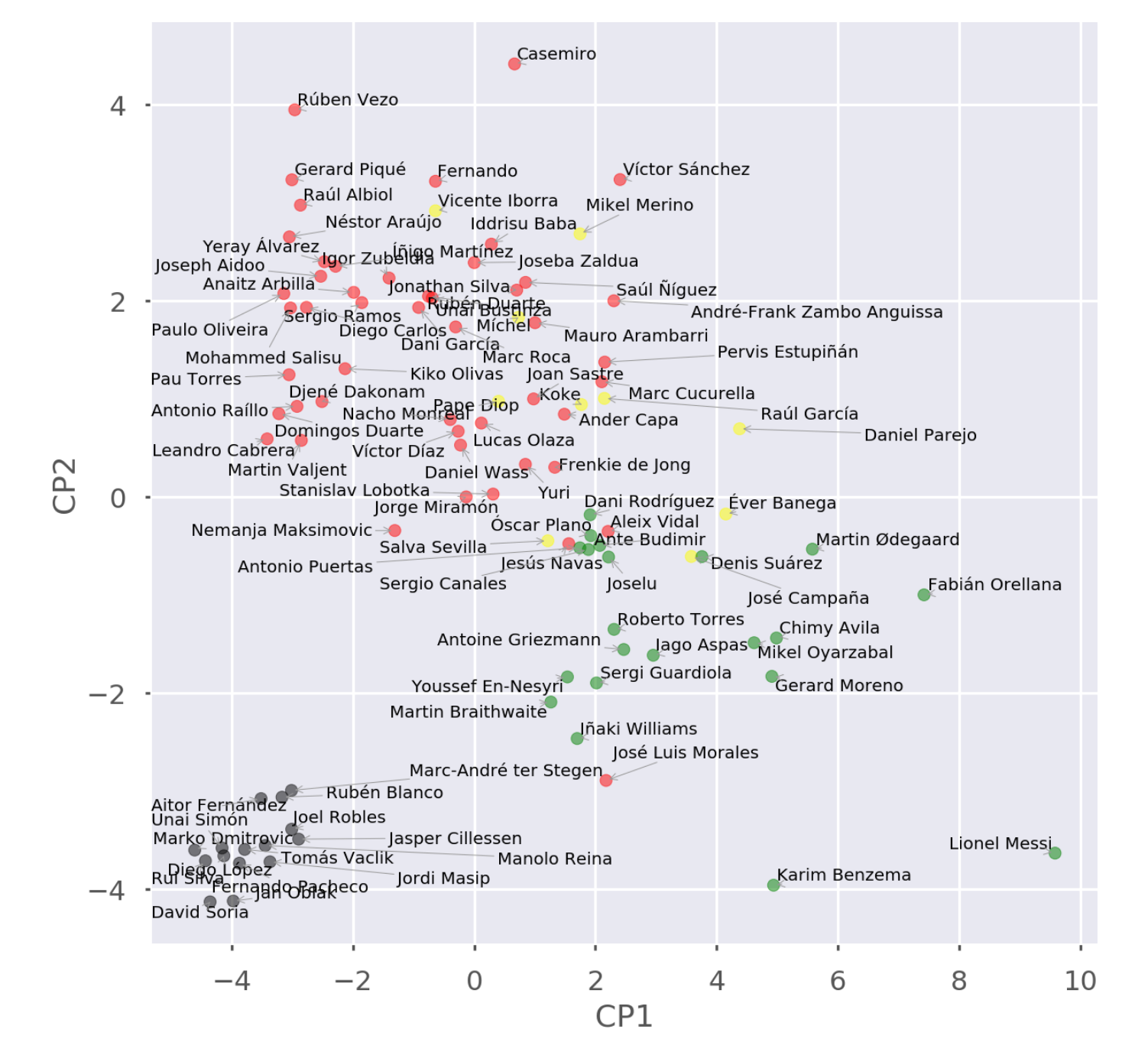
¡Pam! Los jugadores con capacidades parecidas juegan más o menos en las mismas posiciones. Los porteros por un lado, los defensas por otro empezando a mezclarse con los centrocampistas que a su vez se acercan a los delanteros. Y en la esquina, solo, Lionel.
Me llama la atención José Luis Morales, un jugador del Levante que se escapa demasiado de los defensas y se mezcla con los delanteros. Mirando su perfil, veo que ha jugado en todas las posiciones. En mi análisis, usé la primera que aparecía (defensa), pero parece que suele jugar más en la delantera.
Agrupaciones
Visualmente e incluso obviando los colores ya es posible encontrar “grupos” de jugadores. Los de abajo a la izquierda, los solitarios que destacan por la derecha y dos o tres grandes grupos que se mueven por el centro. Pero vamos a ir un paso más allá y encontrar qué piensa un algoritmo de agrupación sobre nuestros jugadores.
Para ello usaremos un algoritmo muy conocido para los que se dedican a jugar con datos llamado “K-Means”. Este algoritmo nos permite agrupar en un número predefinido de “clusters” (grupos) un conjunto de elementos. En nuestro caso, lo que buscamos es que nos agrupe a los jugadores por los Componentes Principales que hemos encontrado antes. Recordemos que la posición en la que juega cada jugador no se usa aquí para nada, y que sólo la hemos usado para colorear los puntos.
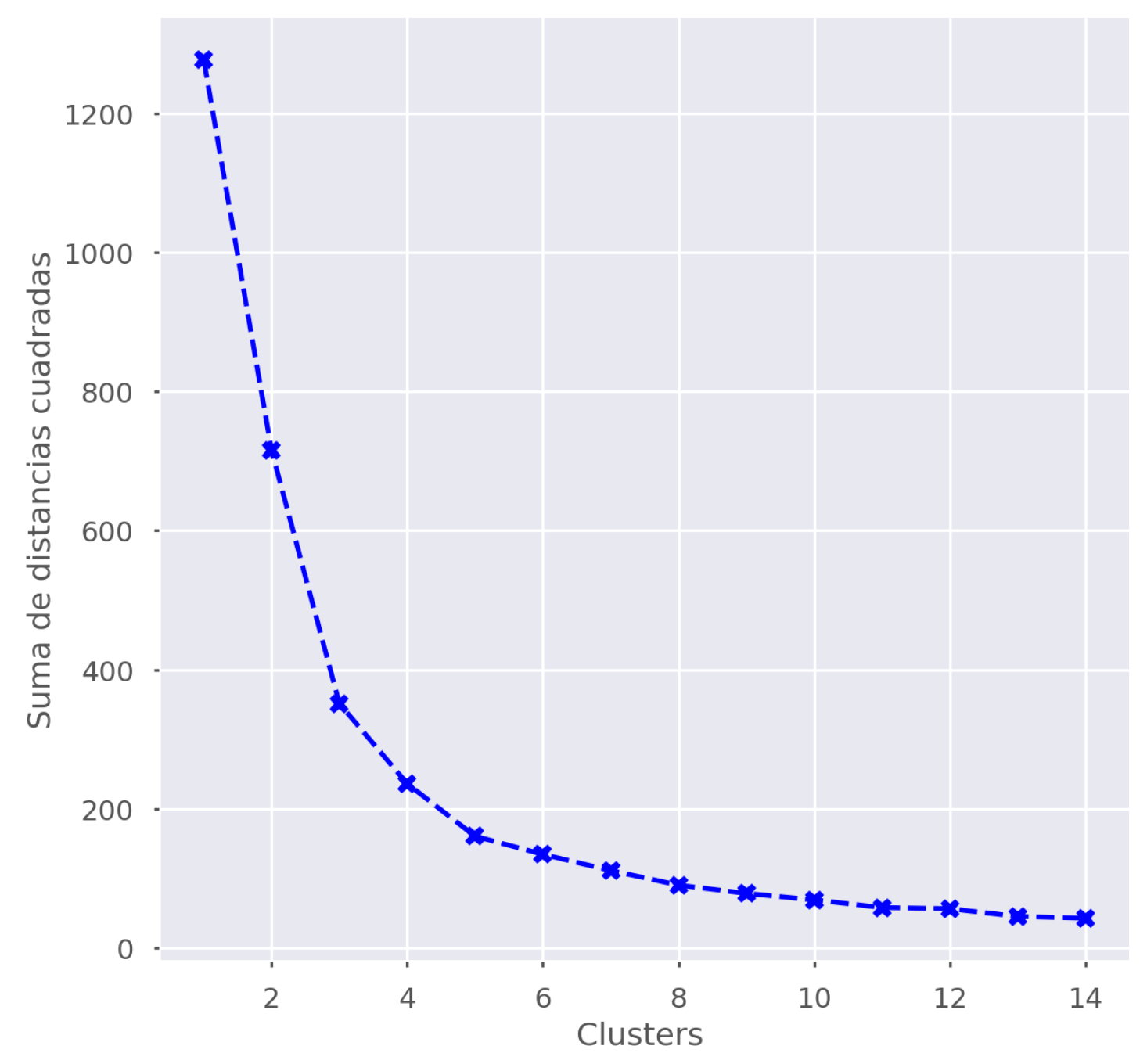
Lo primero que debemos decidir es cuantos grupos queremos crear. Podríamos mirar a ojo el gráfico de las Componentes Principales, pero puestos a tirar de ojímetro mejor lo hacemos con un método semi-científico. Vamos a usar el “Método del Codo” para definir de una forma un poco más formal el número de grupos más óptimo para nuestros jugadores: hay un punto en el que añadir más grupos no añade mucha información de interés. Este método dice que más o menos en la punta del codo, cada nuevo cluster que añadimos es poco diferente del anterior. Hacemos los cálculos con nuestros datos, plantamos en un gráfico… ¡y mi ojímetro me dice que la punta está en el 5!
Aplicando el algoritmo de K-Means con 5 clusters obtenemos la distribución siguiente:
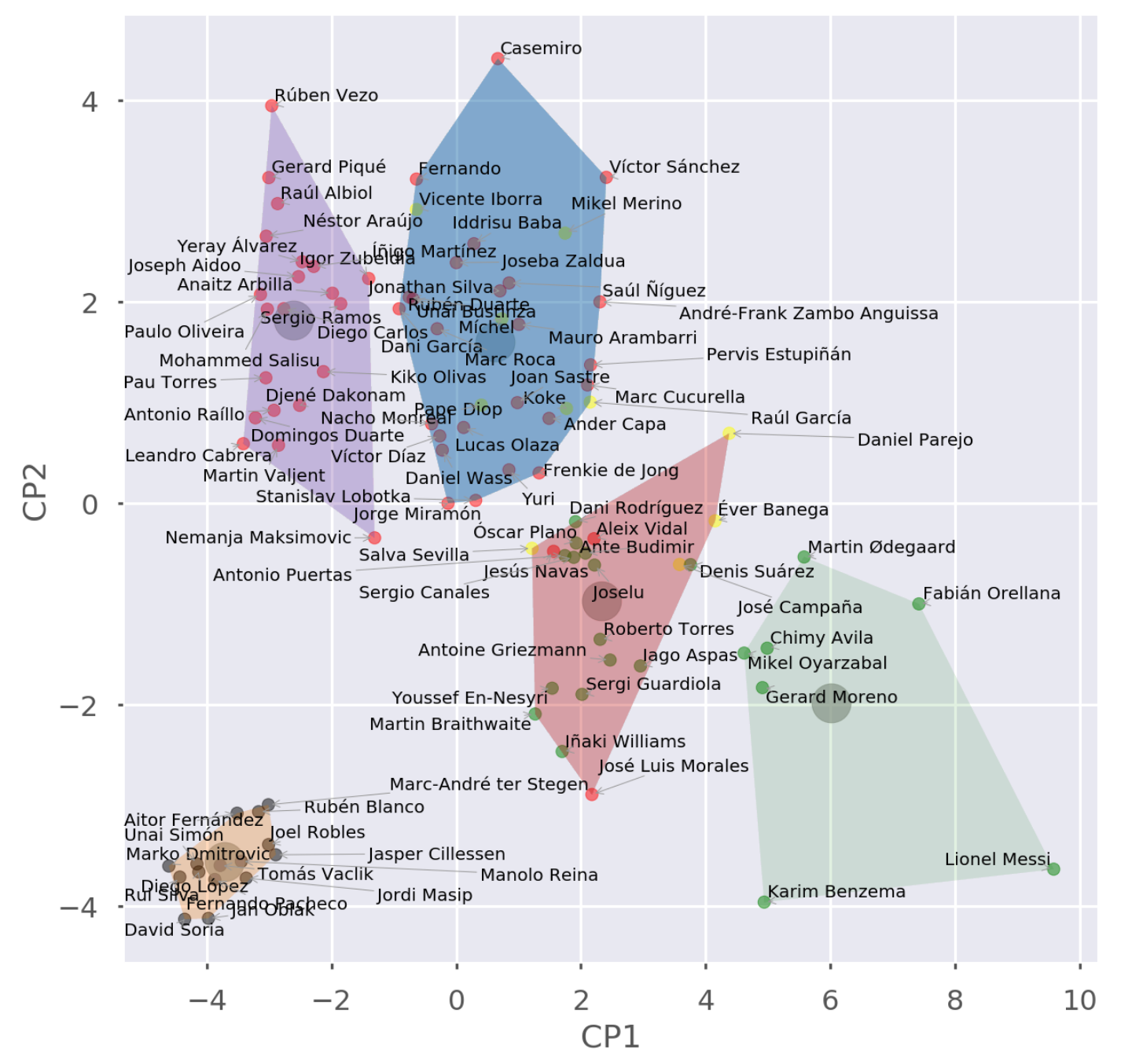
Y así queda la cosa. 5 grupos de jugadores que a partir de ahora me vendrán genial en las comidas con amigos, donde podré hablar de cómo Casemiro es un máquina, de cómo Messi y Benzema son unos fueras de serie o de cómo Jose Luis Morales es capaz de jugar donde quiera.
Para nada esto pretende ser un estudio exhaustivo (¡es finde!). Hay mejores algoritmos y configuraciones que habrían dado resultados más exactos. Espero que mis compañeros de Data Science de Strands no se me echen encima.
Todo ha sido desarrollado con Python como lenguaje, Jupyter Lab como IDE y notebook, Pandas para manejo de los datos, sklearn como librería de Machine Learning, scipy como librería científica y matplotlib como librería gráfica. Además, he usado Selenium para recogida de datos y una base de datos MSSQL en Azure para algunas pruebas “en relacional”.
He subido el código y los datos a github.
En el desarrollo de este estudio he usado información de diversas fuentes: